4/12 DATABASE - 배운 것
#DUAL
간단히 말해 테이블(VIEW)인 척 해주는 것이다.
간단한 계산이나 쿼리 확인용으로 많이 쓰인다.

#NVL(NULL VALUE LESS) AND AS
--NVL(값1,값2) : 값1이 NULL이면 값2로 교체 <오라클>
--IFNULL(값1,값2) <MYSQL>
--ISNULL(값1,값2) <MSSQL>
--AS+명칭 : SELECT에서만 사용가능
SELECT ENAME, SAL, COMM, SAL + NVL(COMM,0) AS REAL
FROM EMP
--결과 REAL컬럼에서 COMM이 NULL 이면 0처리라서 그대로 SAL 값이 고대로 나온다.
--REAL SAL로 작성하면 띄어쓰기 때문에 다른 문법으로 인식 -> " "로 묶는다.
--' '는 문자열 " "는 문법
SELECT ENAME, SAL,COMM,SAL+NVL(COMM,0) AS "REAL SAL"
FROM EMP;NULL + a는 NULL이다.
#문자열 처리
##문자열끼리 더하기
|| 과 CONCAT을 쓸 수 있다.
--문자열 더하기
SELECT 'HELLO' || 'WORLD!!' || '!!'
FROM DUAL
;
--출력 : HELLOWORLD!!
--CONCAT 문자열 더하기 필요는 없음
SELECT CONCAT ('HELLO', 'WORLD!!')
FROM DUAL
;
##문자열 자르기
SUBSTR 을 사용하고 방법은 두가지가 있다.
--자르기
--몇 번째부터 보여줄 것인지(4번째의 다음이 아니라 4번째 부터 보여준다.)
SELECT SUBSTR('HELLO WORLD!!', 4)
FROM DUAL
;
SELECT SUBSTR('HELLO WORLD!!', 8, 5)
FROM DUAL
;##길이
자바와 같이 LENGTH를 사용한다 대신 LENGTH('KEY')와 같은 형식이다.
컬럼으로 사용하게 되면 ''가 필요 없다.
##변경
REPLACE를 사용하게 되는데 크게 두가지형태로 가져갈 수 있다.
-변경
SELECT REPLACE ('HELLO WORLD!!', 'L', 'K')
FROM DUAL
;
SELECT REPLACE('KKKKI', 'K', 'J')
FROM DUAL;
##글자 순번 찾기
INSTR로 찾을 수 있으면 해당 문자의 위치가 숫자 값으로 반환된다.
찾는 글자가 없으면 0이 반환된다. 찾는 방법은 네가지가 있다.
SELECT INSTR('KWON', 'N')
FROM DUAL;
-- N의 위치를 찾는다 K의 위치는 1번이다.
SELECT INSTR('HELLO WORLD!!', 'K')
FROM DUAL;
-- 몇번 째 글자인지찾기
SELECT INSTR ('HELLO WORLD!!', 'L',4)
FROM DUAL
;
--출력 : 4번째 글자 뒤부터 해당 문자의 위치를 찾는다.
SELECT INSTR ('HELLO WORLD!!', 'L',4, 2)
FROM DUAL
;
--출력 : 4번째 이후에 있는 1번째 말고 2번째 문자의 위치를 반환해준다.
-- 2번째 나오는 게 없으면 그대로 0 출력##TO_NUMBER
숫자로 변환해준다.
--숫자로 변환
SELECT TO_NUMBER('123') +4
FROM DUAL
;
SELECT '123' + 4
FROM DUAL
;
둘다 답은 127이다
##대소문자
LOWER 소문자 UPPER 대문자이다. 둘다 문법은
LOWER or UPPER('문자') 이다.
##날짜 처리
--문자열을 날짜로 변환
SELECT TO_DATE('2021-04-09')
FROM DUAL
;
--출력 : 값으로 보면 달력 날짜로 표시
SELECT '2021-04-09'
FROM DUAL
;
--출력 : 그냥 값으로 표시
--현재시간
SELECT SYSDATE
FROM DUAL
;## 날짤 처리
--TO_CHAR(SYSDATE,'형태')
-- 해당날짜를 내가 정한 형태로 출력시켜줘!
--문자열 형태변화 TO_CHAR(값, 형태)
--Y , YY, YYYY: 연도
--MM : 월
--MON : 월
--DD : 일
--DAY : 요일
--D : 몇번 째 날
--유의사항 TO-CHAR 사용 시 형태에 한글 사용 안됨
-- -(하이픈), :(콜론), .(점), ,(컴마) 사용 가능
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD-DAY D')
FROM DUAL
;
--출력: 2021-04-09, 금요일, 1
--AM,PM : 오전 ,오후
--HH : 시간 (12시간 기준)
--HH24: 시간 (24시간 기준)
--MI : 분
--SS : 초
SELECT TO_CHAR(SYSDATE, 'AM HH: MI :SS')
FROM DUAL
;
--출력: 오후 04:25: 15
--몇 주차
--W : 해당 월의 1일 기준 몇주차인지
--WW : 1월 1일 기준 몇주차 인지
-- IW: 첫째 월요일 기준 몇주차 인지
SELECT TO_CHAR(SYSDATE, 'W'),TO_CHAR(SYSDATE, 'WW'),TO_CHAR(SYSDATE, 'IW')
FROM DUAL
;
--출력: w: 2 ww:15 Iw :14
--Q : 분기
SELECT TO_CHAR(SYSDATE, 'Q')
FROM DUAL
;
--출력: 2
--날짜 + -숫자 : 해당일자 만큼 증감
--숫자 기준으로 날짜 빼줌
SELECT SYSDATE -30
FROM DUAL
;
--출력 : 4월9일 기준으로 21-03-10
--TO_CHAR에서 형태에 9가 오는 경우 해당 위치에 숫자를 넣는다는 의미
-- 소수점을 표시할 경우 아래 자리수는 자동 반올림
-- L : 해당 오라클 설치 장치의 언어 셋팅에 따른 통화기호제공
SELECT TO_CHAR(123456, '999999')
FROM DUAL;
--출력 : 123456, 9가 자리수 보다 적으면 #으로 나옴
SELECT TO_CHAR(123456.789, 'L999,999,999.99')
FROM DUAL
;
--출력: ₩123,456.79##값처리
DBMS_RANDOM.VALUE(값1,값2) : 값1부터 값2까지 사이의 난수를 구한다.
DBMS_RANDOM.STRING(형태,개수) : 형태로 지정된 규칙대로 개수만큼 불특정 문자열을 만든다. 비밀번호 설정 시 사용
형태의 종류 :: U : 대문자 , L : 소문자 , A : 대소문자, X : 대문자숫자, P : 출력 가능한 모든 경우의 수
##CASE
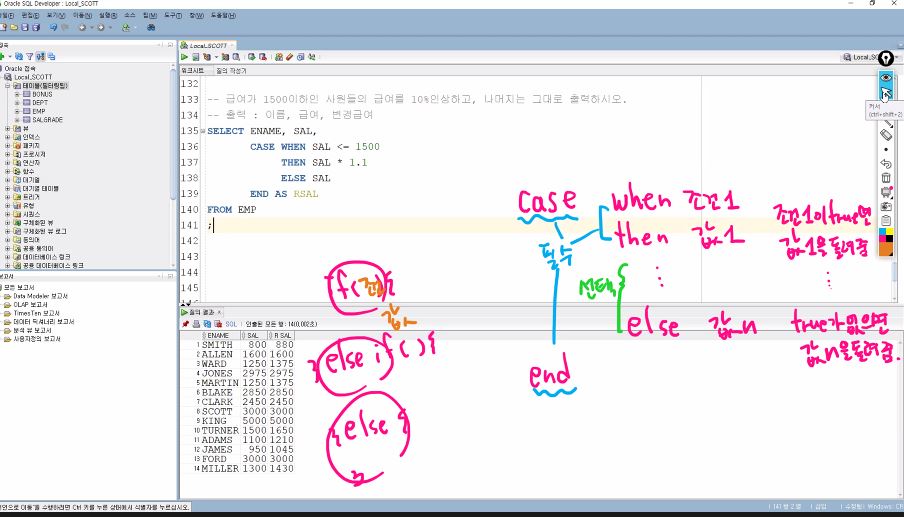
--급여가 3000이상인 사원들의 급여를 10% 인상하고, 나머지는 그대로 출력하시오.
--출력 : 이름, 급여, 변경급여
--CASE WHEN 조건1 THEN 값1 ELSE 값 N :
--조건 1이 TRUE면 값1을 돌려줌. TRUE가 없으면 값N을 돌려줌
--CASE WHEN THEN END 필수, ELSE 선택
SELECT ENAME, SAL,
CASE WHEN SAL >= 3000
THEN SAL * 1.1
ELSE SAL
END AS REAL
FROM EMP;
--출력 : 3000이상 사원들 급여 10&인상
-- 미만인 사람들은 인상없이 원래급여 나옴##DECODE
기본적으로 자바에서의 SWITCH와 동일하며
값이 값1과 같으면 값1-1을 돌려주고 값이 같은 것이 없으면 N을 돌려준다.

SELECT ENAME, JOB, SAL,
DECODE(JOB, 'CLERK', SAL * 1.1, SAL) AS RSAL
FROM EMP;#순차함수 : 지정된 순서대로 데이터를 나열
- ROW_NUMBER : 정렬 후 줄번호 할당
- RANK : 순위를 지정. 단, 동률이 있는 경우에 그 개수만큼 건너뛰어 번호를 할당한다.
- DENSE_RANK : 순위를 지정. 단, 동률이 있는 경우 다음에 숫자를 이어서 번호 할당
작성법
기본
순차함수명() OVER(OREDER BY 값 정렬기준, ~~)
파티션
순차함수명() OVER (PARTITION BY 기준값,~~ OREDER BY 값 정렬기준,~~)
일반적인 순차함수는 대게 SELECT문에서 많이 쓰인다. 기본 순차함수 작성에서는 어떤 값을 어떤 기준으로 순서를 정할 것인가이다. 하지만 파티션 작성은 이에 더 나아가 정렬로써 한번더 여과과정을 거친다. 예를 들어 어떠한 테이블을 월급 순서대로 정렬했다고 치자. 하지만 나는 직업별로 월급의 순위를 보고 싶다면 어떻게 할까? 이럴때 파티션을 쓴는 것이다.
SELECT ENAME,SAL,JOB,EMPNO,
RANK() OVER(PARTITION BY JOB ORDER BY SAL DESC) AS RNK
FROM EMP
;이 SELECT 문을 실행 시킨다면 직업별로 1등부터 N등까지 나눌 수 있다.
#JOIN - 데이터 + 데이터 FROM 에서만 사용가능

PRIMARY KEY : 고유값이다
FOREIGN KEY : 특정 PK와 관계를 가진 컬럼(종속적)
자가참조 : 값이 있어도 되고 없어도 되는 참조(NULL)
직접참조 : 완전히 같은 참조 DEPTNO=DEPTNO
간접참조 : 범위 참조를 이야기한다. SAL BETWEEN LOSAL AND HISAL
- A inner join B on 조건 : A,B 두개의 데이터를 붙이고 조건을 걸어 필터링한다.(기본적으로 곱연산이다)
- A left outer join B on 조건 : AB의 공통된 데이터와 A의 데이터를 합치고 조건으로 필터링한다.
- A right outer join B on 조건 : AB의 공통된 데이터와 B의 데이터를 합치고 조건으로 필터링한다.
** inner and outer 구분 법
inner는 추가정보를 가진 회원만 뽑아네고
outer는 회원정보를 모두 띄우고 추가정보가 없을시 null로 표현
두개 이상을 join 한다면
SELECT *
FROM EMP E INNER JOIN DEPT D
ON E.DEPTNO = D.DEPTNO
INNER JOIN SALGRADE SG
ON E.SAL BETWEEN SG.LOSAL AND SG.HISAL
AND D.LOC ='CHICAGO'위처럼 두개 이상의 조인이 필요하다면 FROM은 따로 쓸필요없고 INNER JOIN을 연속으로 사용해주면 된다. 그리고 ON 조건 뿐만아니라 조건이 더 필요하다면 AND 이후에 필요한 조건을 작성해주면된다.
오늘 수업의 TIP
쿼리를 작성할때 데이터를 작게 작게 나눠서 비교할 수 있게 만들어야한다. 이유는 큰데이터를 한번에 정렬하는 것보다 작은 데이터로 쪼개서 정렬하며 완성해 나가는 것이 프로그램을 돌리는데 컴퓨터가 벅차지 않다.